.svg)


La manière dont le monde accède à l’information est en train de changer de nature. Les moteurs de recherche génératifs, portés par des modèles de langage (LLM), ne relèvent plus de l’expérimentation. Ils transforment déjà la façon dont les marques sont découvertes, comparées et recommandées.
Dans ce contexte, le SEO traditionnel reste nécessaire, mais il devient insuffisant. La visibilité ne se joue plus uniquement dans des pages de résultats, mais dans la capacité d’un site à être sélectionné, repris et cité dans une réponse générée.
C’est précisément l’objectif du GEO (Generative Engine Optimization) : optimiser un écosystème digital pour devenir une source exploitable par les moteurs IA. Pour le maîtriser, nous devons comprendre le moteur d’exploration des IA : le Query Fan-Out.
Ce qu’est le Query Fan-Out, et pourquoi il change la donne
Le Query Fan-Out désigne le mécanisme par lequel un moteur IA transforme une intention utilisateur en plusieurs requêtes internes, afin d’explorer le web sous différents angles. Concrètement, le moteur ne se contente pas de “chercher votre question”. Il découpe l’intention, génère des variantes, teste des formulations, puis collecte des sources.
Dans une logique GEO, cette nuance est structurante : nous ne gagnons pas la visibilité en répondant uniquement au prompt final, mais en étant présents sur les requêtes intermédiaires que le fan-out active.
Comment les moteurs IA construisent une réponse : le pipeline opérationnel
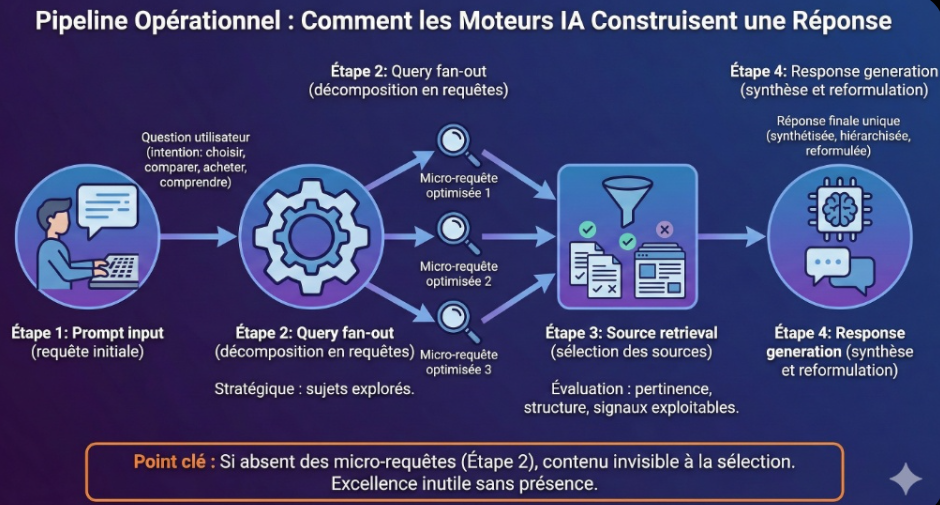
Pour influencer une réponse générative, il est essentiel de comprendre le pipeline de génération. Nous n’avons pas besoin d’entrer dans l’implémentation technique, mais nous devons comprendre la logique qui détermine quelles sources seront utilisées.
Étape 1. Prompt input (requête initiale)
Tout commence par l’utilisateur. Il formule une question souvent conversationnelle. Elle peut être imprécise, mais elle contient toujours une intention : choisir, comparer, acheter, comprendre.
Étape 2. Query fan-out (décomposition en requêtes)
C’est l’étape la plus stratégique. Le moteur transforme le prompt en plusieurs micro-requêtes optimisées qu’il envoie vers des moteurs de recherche traditionnels. Cette étape détermine les sujets réellement explorés.
Étape 3. Source retrieval (sélection des sources)
À partir des résultats, le moteur sélectionne et évalue les sources jugées pertinentes. La sélection n’est pas neutre : elle dépend de la capacité des pages à répondre à l’intention, à structurer l’information, et à apporter des signaux exploitables.
Étape 4. Response generation (synthèse et reformulation)
Le moteur synthétise les informations collectées, les hiérarchise, les reformule, puis génère une réponse unique. La réponse finale est un produit de sélection et de consolidation.
Point clé : si nous ne sommes pas présents sur les micro-requêtes générées à l’étape 2, notre contenu n’entre pas dans la phase de sélection des sources. Nous pouvons être excellents, mais invisibles.
Les chiffres clés des Query Fan-Out : ce que révèlent l'étude de 50 000 prompts
Nous avons analysé plus de 50 000 prompts français afin de mieux comprendre comment fonctionnent les query fan out.
Tableau de synthèse
Longueur des query fan out
- 2 queries : 74,52 %
- 3 queries : 21,12 %
- 4 queries : 4,26 %
Nous observons aussi une corrélation nette : plus le fan-out augmente, plus la longueur moyenne des queries diminue. En moyenne :
- 2 queries : 95,1 caractères par query
- 3 queries : 79,7 caractères par query
- 4 queries : 66,7 caractères par query
Lecture stratégique : quand l’intention devient complexe, le moteur découpe en micro-requêtes. Il passe d’une logique “thématique” à une logique “critères”.
La similarité confirme ce comportement. À 2 queries, la similarité est faible, ce qui indique une exploration de deux axes distincts. À 3 queries, la similarité augmente, ce qui indique davantage de reformulations et d’ajout de contraintes, donc une stratégie de validation.
Le choc du multilinguisme : la stratégie du miroir
L’un des enseignements les plus structurants de l’étude est le multilinguisme massif. Sur des prompts formulés en français, les moteurs déclenchent très souvent des recherches en anglais.
- 56,96 % des prompts français déclenchent au moins une query en anglais
- Dans le cas le plus fréquent, 2 queries, le multilingue monte à 61,6 %
Lecture stratégique : lorsque le fan-out est de 2 queries, le moteur adopte souvent une logique de validation linguistique, avec une query en français et une query en anglais, ou une variation proche. Cela signifie qu’une marque uniquement visible dans l’écosystème francophone se prive d’une partie importante de ses chances de citation.
Autre point important : lorsque le fan-out monte à 3 ou 4 queries, le moteur traduit moins et varie davantage sur des reformulations proches. Il cherche à resserrer les critères plutôt qu’à dupliquer la requête dans une autre langue.
Les intentions dominantes : pourquoi “best” et “top” structurent les réponses IA
En analysant les ouvertures de requêtes, un pattern ressort immédiatement. Les premiers mots les plus fréquents incluent notamment des termes de recommandation comme best, how, top, meilleures, comment. Lecture : le moteur ne se limite pas à informer, il cherche à aider à décider.
Nos données sur les intentions explicites dans les queries confirment cette dynamique :
- best / top / meilleur : 22,20 %
- avis / review / rating : 8,15 %
- prix / pricing / price : 4,42 %
- comparatif / compare : 3,94 %
- définition / what is : 2,35 %
- intent local : 1,33 %
- vs : 0,94 %
Implication : les contenus “descriptifs” sont structurellement moins utiles pour le moteur. Les formats les plus stratégiques sont ceux qui permettent de classer et comparer : classements, comparatifs, pages d’avis structurées, pages pricing lisibles, et contenus d’aide au choix.
Les chiffres et les années sont secondaires
Contrairement à certaines croyances SEO, les chiffres et les années apparaissent peu dans les queries : environ 7,48 % des queries contiennent un chiffre, et 2,29 % mentionnent une année. Ils peuvent aider dans des cas précis, mais ils ne sont pas le cœur du fan-out.
Similarité entre queries : ce que cela dit du comportement du moteur
Nous mesurons la similarité entre les queries d’un même prompt sur une échelle allant de 0 (aucun recouvrement) à 1 (identiques). La similarité moyenne observée est de 0,203.
- 2 queries : 0,127
- 3 queries : 0,273
- 4 queries : 0,247
Lecture : à 2 queries, le moteur explore deux directions distinctes. À 3 queries, il reformule plus et ajoute des contraintes. À 4 queries, il maintient une logique d’affinage, mais avec davantage de micro-variantes. Cela nous indique comment structurer une stratégie de contenus : couvrir des axes, puis couvrir des critères.
Les Query Fan-Out pour le e-commerce
Sur l’e-commerce, le Query Fan-Out ne sert pas uniquement à trouver des contenus. Il sert aussi à générer les carrousels produits ChatGPT.

Deux familles de requêtes : “source queries” et “product queries”
Quand ChatGPT déclenche un carrousel produits, nous observons un workflow récurrent :
- Query fan-out orienté sources (source queries)
Le moteur transforme le prompt initial en variantes, synonymes et intentions afin d’identifier des pages qui “rankent” sur Google et Bing (comparatifs, avis, guides d’achat). Objectif : trouver des contenus tiers qui listent des produits ou des références exploitables. - Extraction des produits depuis ces sources
Une fois les pages identifiées, le moteur parcourt leur contenu et extrait des noms de produits (ou des références suffisamment stables pour être recherchées). - Query fan-out orienté produits (product queries)
À partir des noms extraits, le moteur génère de nouvelles requêtes, cette fois-ci centrées sur les produits. Ces requêtes servent à interroger Google Shopping afin de récupérer prix, marchands, disponibilité et métadonnées (organique et ads).
Lecture : le carrousel est le résultat d’une double sélection. Les sources déterminent quels produits sont candidats, puis Shopping détermine quelles options d’achat et quels marchands sont affichés.
Un détail intéressant apparaît dans les données techniques : dans certaines traces, on retrouve un champ reflétant la requête utilisée pour déclencher cette mécanique (souvent nommé request_query). Cela confirme que le produit affiché n’est pas choisi au hasard : il est le résultat d’un chemin de requêtes, de sources, puis d’un passage par Shopping.
Checklist de visibilité e-commerce
- Optimisation du flux Shopping : indispensable pour la correspondance prix, stock et variantes.
- Pricing accuracy : cohérence stricte entre ce que disent les sources (prix, gamme, attributs) et ce que remonte Shopping.
- Positionnement “best-of” : être listé par des tiers (médias, comparateurs) afin d’être extrait à l’étape d’identification des produits.
- Naming structuré : dénominations produits stables, identiques et reconnaissables partout (sources tierces, site, feed, marchands).
Implication stratégique : en e-commerce, il ne suffit pas d’optimiser des pages catégories ou des fiches produit. Nous devons aussi nous assurer d’être présents dans les sources tierces qui servent de “réservoir” de produits, tout en garantissant une correspondance parfaite côté Shopping pour l’éligibilité et la performance dans le carrousel.
Conclusion
Le Query Fan-Out explique pourquoi certaines marques apparaissent systématiquement dans les réponses IA, et d’autres jamais.
Les moteurs IA ne choisissent pas des sources au hasard. Ils activent un ensemble de requêtes intermédiaires, évaluent des contenus déjà visibles sur ces requêtes, puis consolident ce qu’ils considèrent comme crédible et exploitable. Si un site n’est présent à aucun de ces niveaux, il reste invisible, quelle que soit la qualité perçue de son contenu.
Le GEO est donc un travail d’exposition progressive : être visible sur les requêtes du fan-out, être cité dans les sources utilisées, et maintenir une cohérence entre contenu, autorité et signaux marchands.


.svg)